
Subject: High Pod Unhealthy Rate & Resource Overuse on ap-northeast-1 – Possible Platform Load Issue
Dear Claw Cloud Support Team,
I hope this message finds you well.
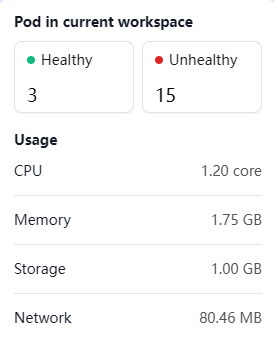
18 Pods in total (3 Healthy, 15 Unhealthy), despite only 1 replica being configured
Severe resource overuse:
CPU: Limit = 0.2 Core → Usage = 1.20 Core
Memory: Limit = 256 Mi → Usage = 1.75 Gi
Application appears unable to stabilize—likely due to OOM kills or throttling.
I understand from your status notice that the ap-northeast-1 infrastructure is currently under heavy load, and deployments may take 3–5 minutes. However, the persistent pod churn and extreme resource overshoot suggest either:
A platform-level scheduling or resource accounting issue, or
An unexpected behavior with how resource limits are enforced (e.g., containers allowed to exceed limits before crash-looping).
Could you please help clarify:
Is this behavior expected under current load conditions?
Are there known issues with resource enforcement or pod lifecycle management in ap-northeast-1?
Would redeploying during off-peak hours (or in another region) likely improve stability?
I'm happy to provide full deployment specs, logs, or screenshots if needed.
Thank you for your support—and for building such an innovative platform!